Dada: A DGraph-Powered Knowledge Sharing Platform for Everyone

I am a app developer who knows a bit of ux design. Building apps for android and web.
Introduction
Dada is an innovative resource discovery platform that leverages DGraph's vector search capabilities to help people find and share valuable content. Whether you're a developer, designer, writer, or any kind of learner, Dada provides an intuitive way to discover and contribute to a growing collection of knowledge resources.

Problem Statement
In today's digital age, finding relevant and high-quality resources is becoming increasingly challenging due to:
- Information Overload: The internet is flooded with content, making it difficult to find truly valuable resources.
2. Scattered Knowledge: Useful resources are spread across different platforms and websites.
Context Loss: Traditional search engines often miss the context and relevance that human curators can provide.
Discovery Challenges: Finding related content or exploring new topics can be cumbersome.
Solution
Dada addresses these challenges through:
1. Semantic Search
Powered by DGraph's vector search capabilities, Dada understands the context of your queries, not just keywords. The search functionality is elegantly integrated into the user interface:
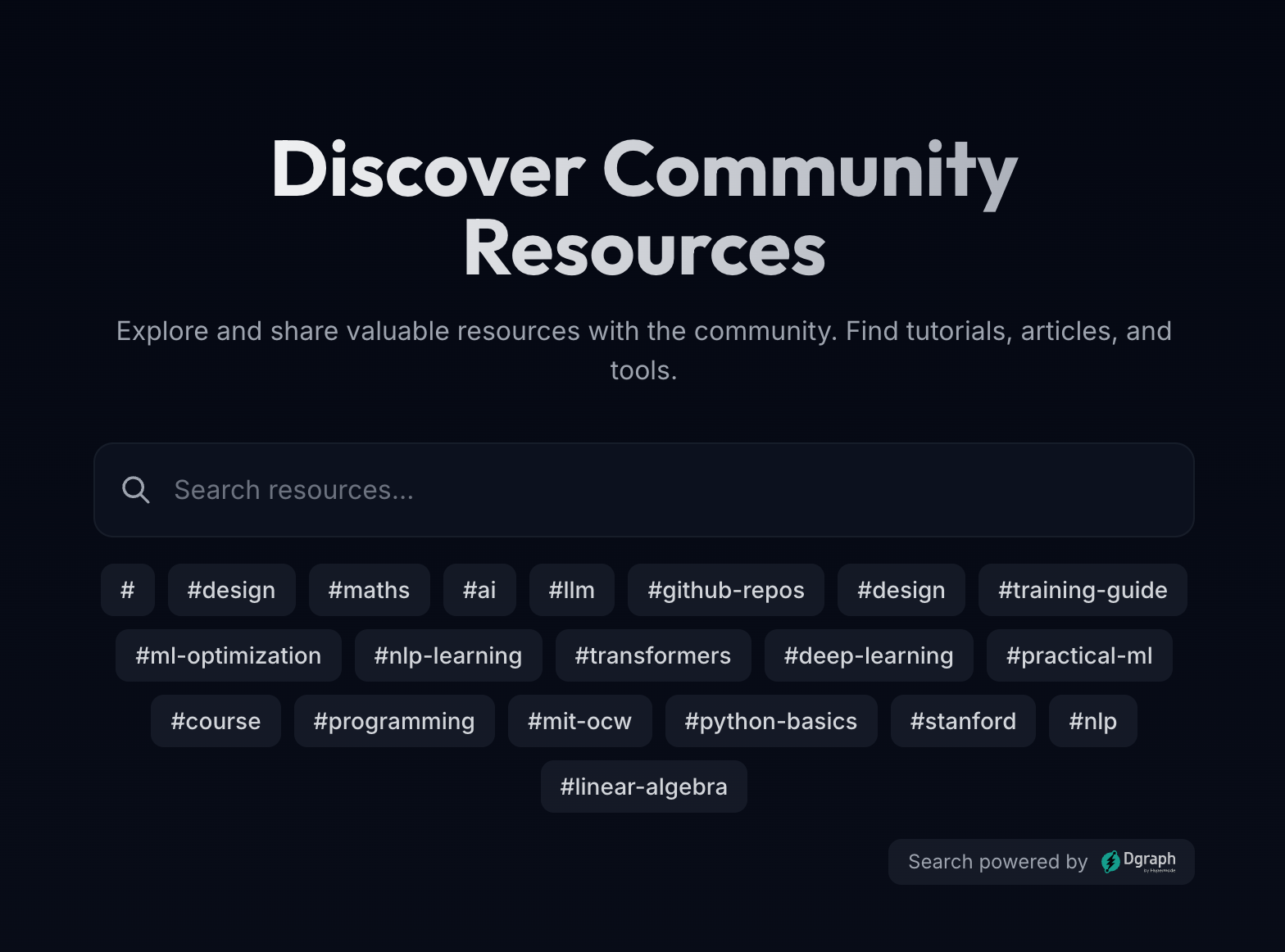
2. Community-Driven Content
Users can easily share and categorize resources:
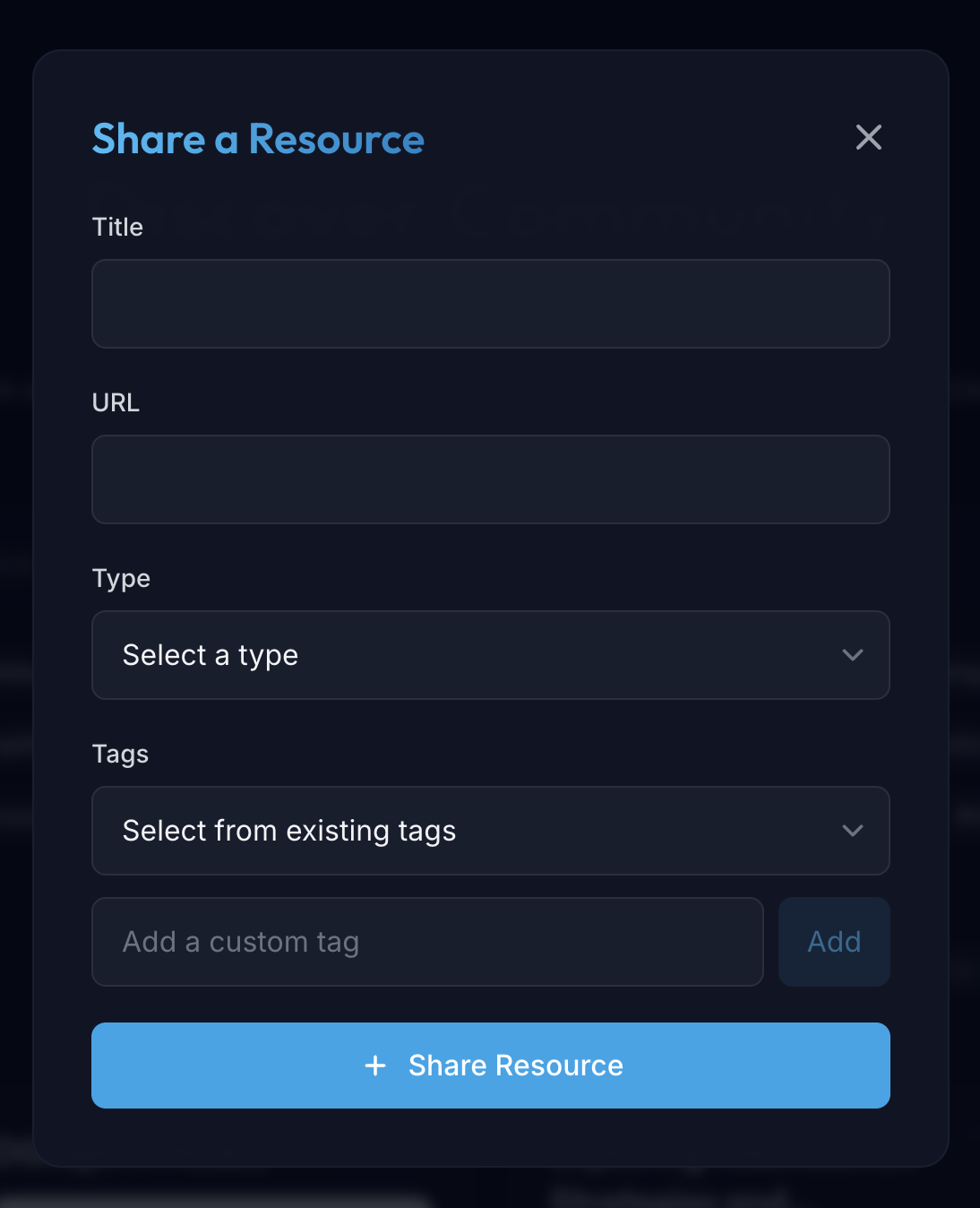
3. Smart Tagging System
An intuitive tagging system helps organize and discover related content:
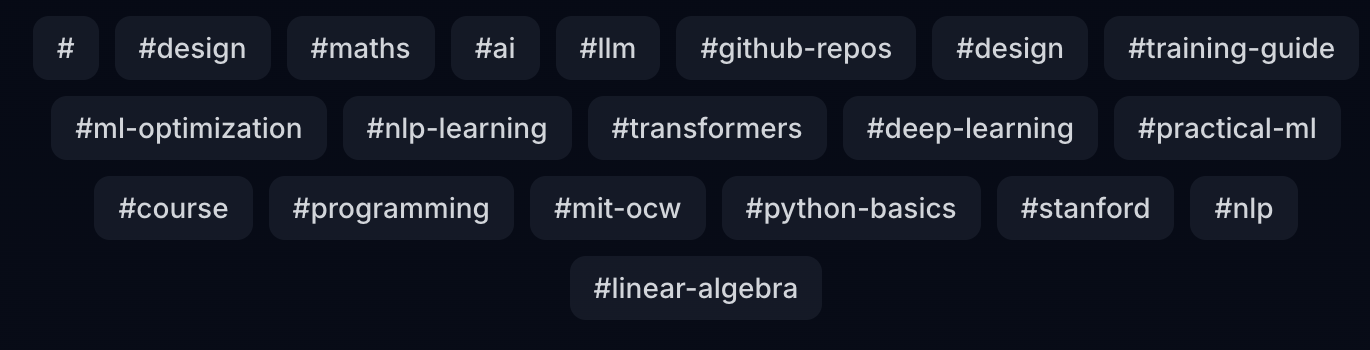
4. Visual Resource Cards
Each resource is presented in an engaging card format with preview images and essential information:
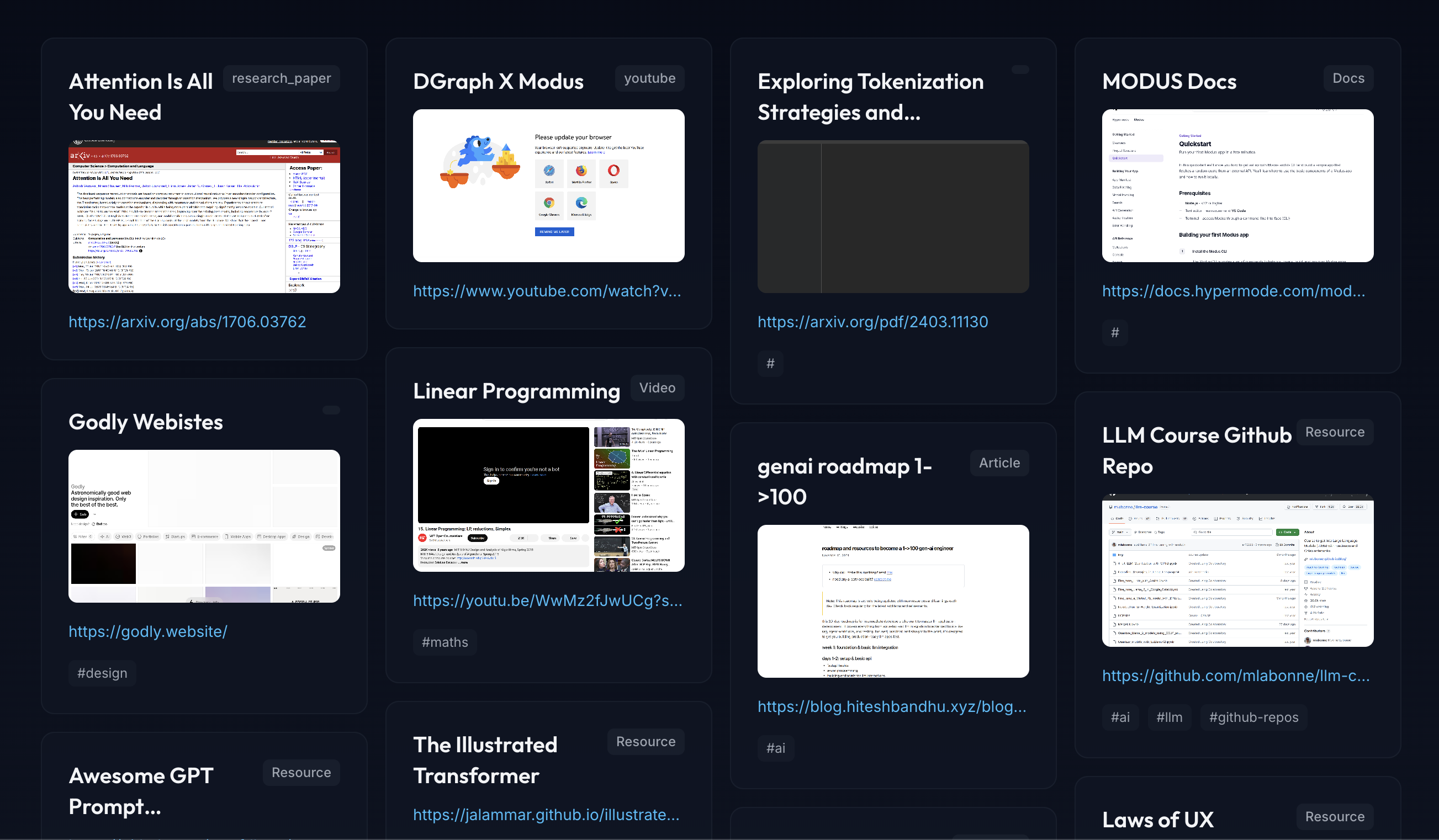
Key Features
Intelligent Search: Context-aware search powered by DGraph's vector embeddings
Resource Sharing: Simple interface for contributing valuable content
Visual Previews: Automatic preview generation for shared resources
Tag-Based Navigation: Intuitive exploration through related topics
Responsive Design: Seamless experience across all devices
Technology Stack
Frontend: React with TypeScript
Search Engine: DGraph with vector embeddings
API: GraphQL
Styling: TailwindCSS
Animations: Framer Motion
Impact
Dada serves as a bridge between content creators and seekers, making knowledge sharing more efficient and accessible. Whether you're:
A student looking for learning resources
A professional seeking industry insights
A content creator wanting to share valuable information
An enthusiast exploring new topics
Dada provides a platform where quality content can be easily discovered and shared.
Technical Deep Dive: Building Dada with Modus and DGraph
Core Architecture
DGraph Vector Database
Schema implements HNSW (Hierarchical Navigable Small World) index for vector similarity search
Content type with vector embeddings for semantic search:
id: string @index(exact) . title: string @index(term) . url: string @index(exact) . type: string @index(exact) . embedding: float32vector @index(hnsw(metric:"cosine")) . type Content { id title url type embedding }
Modus Framework Integration
AssemblyScript-based serverless functions
MiniLM model integration for text embeddings
DGraph gRPC connection configuration:
Here are all the function signatures from the codebase:
Content Management Functions
// Add new content with automatic embedding generation
addContent(content: Content): Map<string, string> | null
// Retrieve content by ID
getContent(id: string): Content | null
// Delete content by ID
deleteContent(id: string): void
// Search content with optional type filter
searchContent(query: string, contentType: string = ""): Content[]
// Get content filtered by type
getContentByType(type: string): Content[]
// Get all content entries
getAllContent(): Content[]
// Get all unique tags in the system
getAllTags(): string[]
// Get content filtered by multiple tags
getContentByTags(tags: string[]): Content[]
// Get content filtered by a single tag
getContentByTag(tag: string): Content[]
Utility Functions
// Generate text embeddings
embedText(content: string[]): f32[][]
// Build content mutation JSON
buildContentMutationJson(connection: string, content: Content): string
// DGraph Utility Functions
searchBySimilarity<T>(
connection: string,
embedding: f32[],
predicate: string,
body: string,
topK: i32,
tags: string[] | null = null
): T[]
searchByTags<T>(
connection: string,
tags: string[],
body: string
): T[]
injectNodeUid(
connection: string,
payload: string,
root_type: string,
schema: GraphSchema
): string
injectNodeType(
connection: string,
entity: JSON_TREE.Obj | null,
type: string,
schema: GraphSchema
): void
deleteNodePredicates(
connection: string,
filter: string,
predicates: string[]
): void
getEntityById<T>(
connection: string,
idField: string,
id: string,
body: string
): T | null
addEmbeddingToJson(
payload: string,
predicate: string,
embedding: f32[]
): string
getAllContents<T>(
connection: string,
body: string
): T[]
Type Definitions
class Content {
id: string
title: string
url: string
type: string
tags: string[]
}
class GraphSchema {
node_types: Map<string, NodeType>
}
class NodeType {
id_field: string
relationships: Relationship[]
}
class Relationship {
predicate: string
type: string
}
class ListOf<T> {
list: T[]
}
Future Vision
1. Personalized Recommendations: Using DGraph's capabilities to suggest relevant content
Content Collections: Allowing users to create and share curated lists
Enhanced Analytics: Understanding content impact and user interests
Multi-language Support: Making knowledge accessible across languages
API Access: Enabling integration with other learning platforms

